
Field Operations That Run Predictably at Scale
Field execution is distributed by nature — across people, locations, and conditions.
What breaks down is not effort. It’s coordination, visibility, and follow-through.
We design the operating model end-to-end, then implement the system that makes it run reliably.
How We Stabilize Field Execution
We don’t start with tools. We start with how work moves — then we design the system that makes execution visible and dependable.
1) Create & assign work clearly
Standardize job creation, ownership, handoffs, and escalation paths — so execution stops relying on memory.
2) Make updates structured
Capture progress, evidence, and blockers in a consistent format — so reporting doesn’t become a separate job.
3) Make execution visible
Give supervisors and leadership a clean view of progress and exceptions — so correction becomes routine.
Before → After (What Changes in Field Ops)
These are operating shifts — not technology claims.
Before
Fragmented • follow-up driven- Status visibility depends on calls, messages, and manual updates.
- Supervisors spend time chasing instead of improving execution.
- Exceptions surface late — usually after SLA or customer impact.
After
Connected • visible • predictable- A single view of jobs, ownership, progress, and exceptions — without chasing.
- Structured updates and evidence capture reduce reporting friction.
- Delays surface early — corrective action becomes routine.
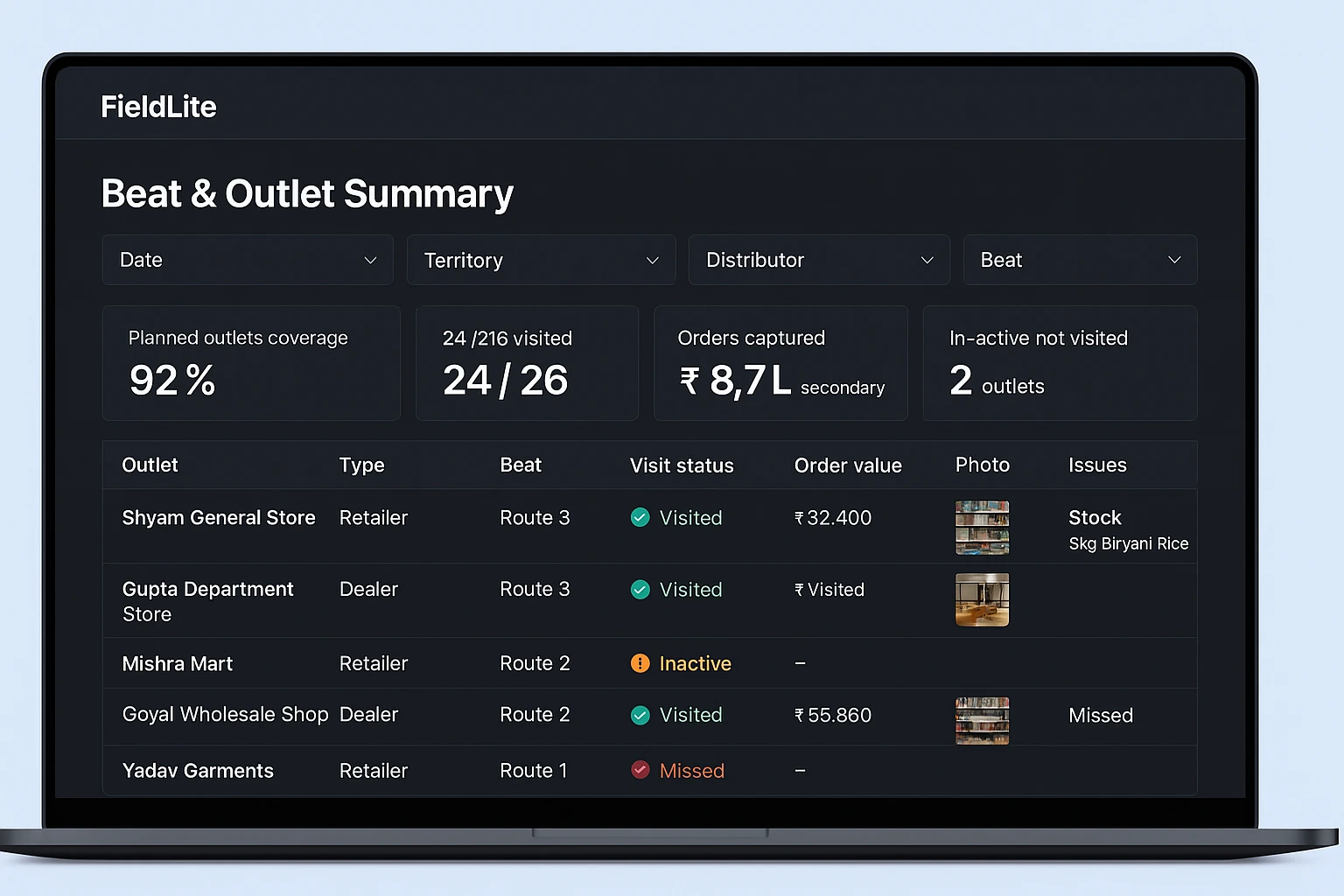
System Layers That Make Field Ops Work
Not every layer is required on day one. We design the blueprint first, then implement what your environment can sustain.
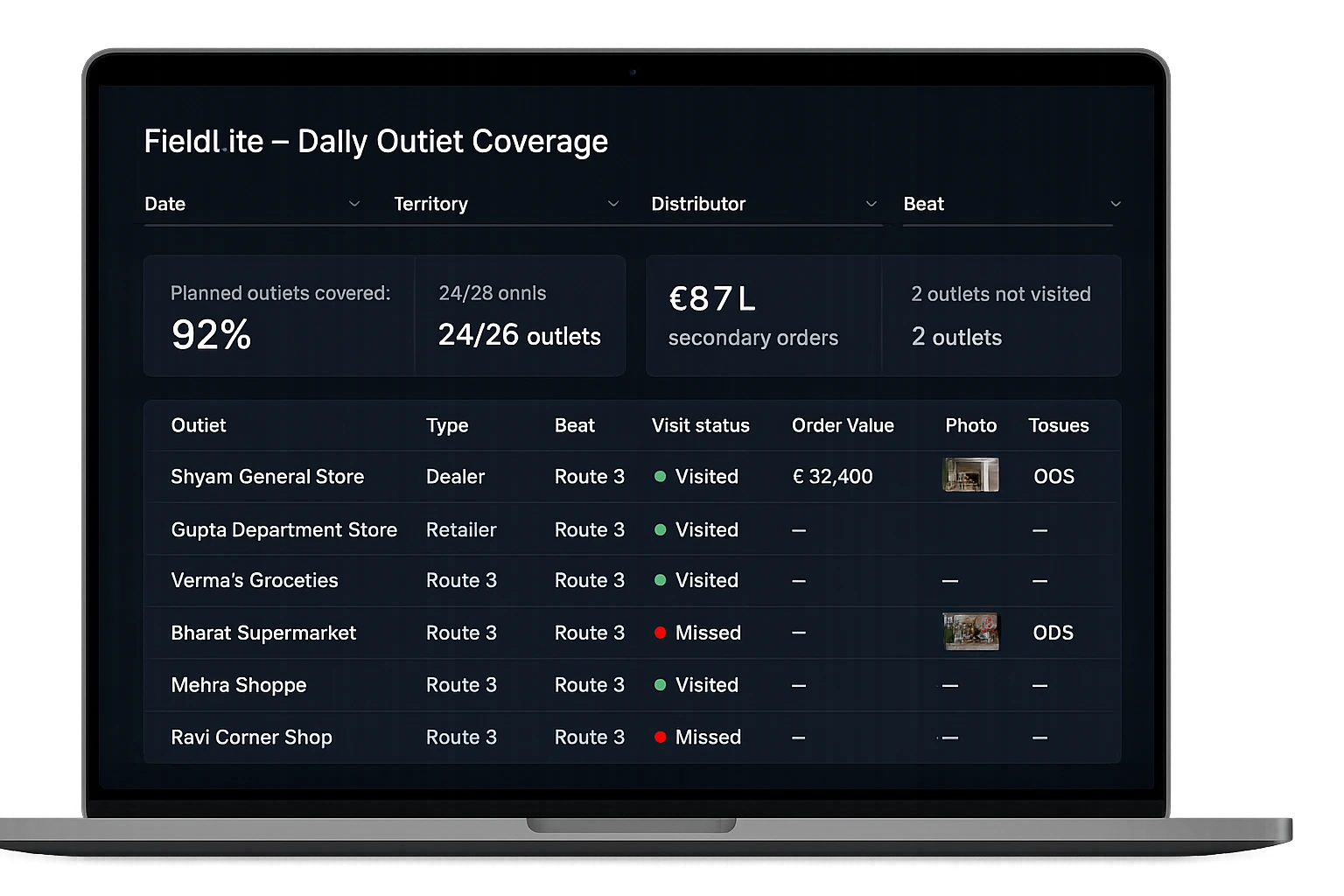
Signals We Typically Deliver
These are directional outcomes observed across field contexts. Real measurement is defined during the Pilot.
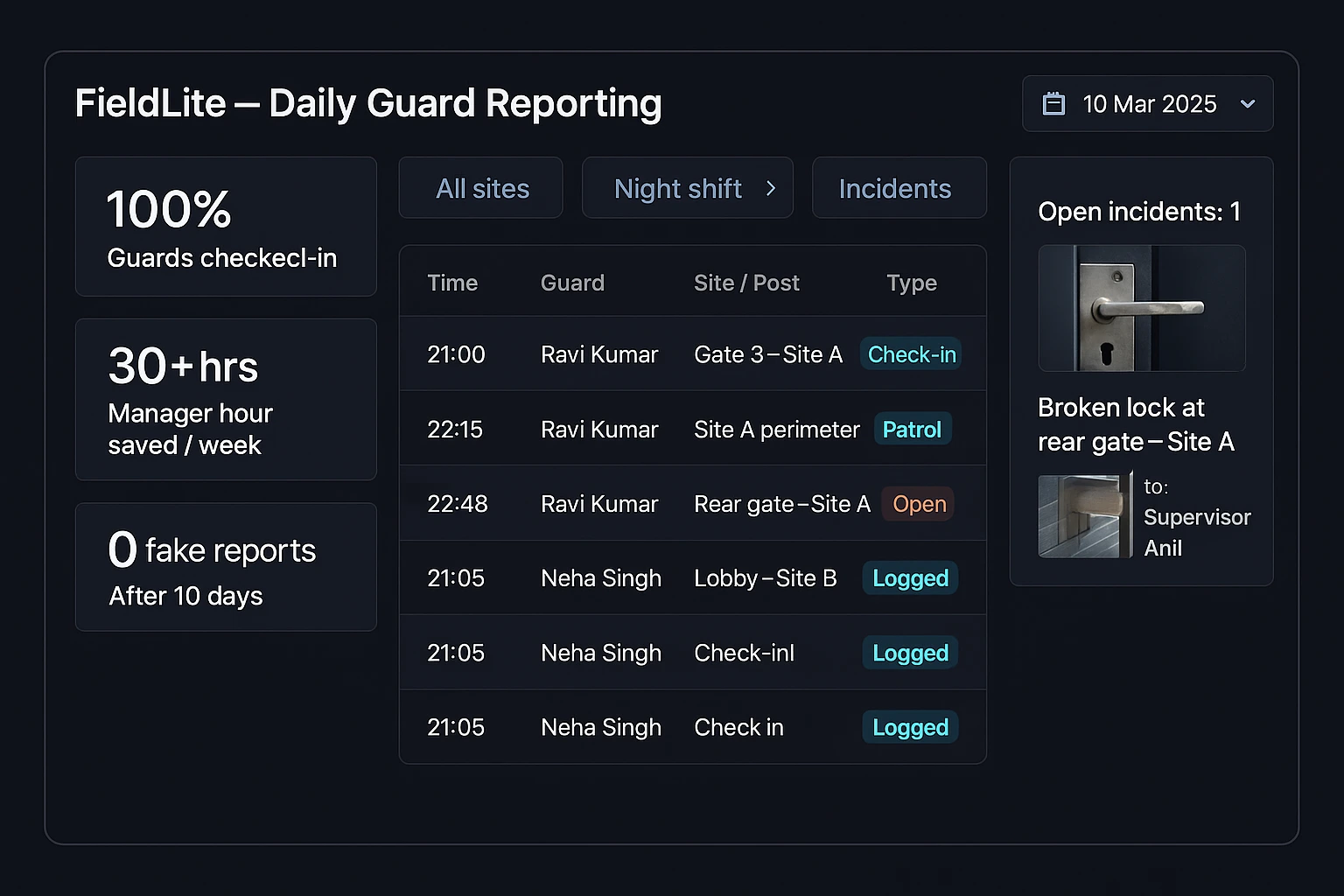
We guide teams to a system that fits how field work actually happens — and that leaders can operate without micromanagement. The Pilot confirms fit, constraints, and measurable impact.
Structured updates replace manual coordination across calls and threads.
Exceptions surface early enough to correct before SLA or customer impact.
Compliance improves when reporting is part of the workflow, not extra work.
Where This Works Best
This is not “industry-only.” It’s where this operating model delivers the strongest leverage.
Works best for
- Distributed teams executing repeatable on-ground work at volume.
- Managers who need visibility without spending the day chasing updates.
- Ops with SLA risk, compliance requirements, or customer-facing timelines.
Not ideal if
- The work is fully ad-hoc with no repeatable workflow to stabilize.
- There’s no operational owner to define process and enforce basic discipline.
- The organization is looking for “a tool” without aligning on the operating model first.
If This Matches Your Operating Reality
The next step is a Pilot — to define measurement, confirm constraints, and validate the operating model before committing to scale.
Start with a Pilot
We map the workflow, define ownership and exceptions, and align success metrics. You get clarity and a blueprint — not a sales pitch — before any build begins.



