
Internal Ops That Runs Without Chasing — And Reports Without Manual Work
Most internal operations don’t fail because people don’t work.
They fail because ownership is unclear, updates are fragmented,
approvals slow down, and reporting becomes manual.
We design the internal operating model — then implement the system that makes execution visible,
exceptions obvious, and reporting consistent across teams and locations.
How We Stabilize Internal Ops
We don’t start by “adding tools.” We start with how work requests enter, how ownership moves, how approvals happen, and how reporting is produced — then we make that flow predictable.
1) Standardize inputs and ownership
Normalize requests, updates, and evidence across WhatsApp, email, and teams — with consistent fields, owners, and timestamps.
2) Make approvals and SLAs visible
Define approval paths, escalation rules, and SLA thresholds so exceptions surface early — before they become escalations.
3) Automate reporting packs
Generate daily/weekly/monthly summaries from structured signals — including exceptions, closures, SLA health, and evidence trails.
Before → After (What Changes in Internal Ops)
These are operating shifts — not platform claims.
Before
Fragmented • chase-driven- Work requests land everywhere — ownership and status are unclear.
- Approvals depend on follow-ups — SLAs slip silently.
- Reporting is compiled manually — trust in metrics is low.
After
Visible • controlled • report-ready- Every item has an owner, status, and evidence — with an audit trail.
- Approvals and escalation run by rules — exceptions surface automatically.
- Reporting packs generate on schedule — leadership sees reality early.
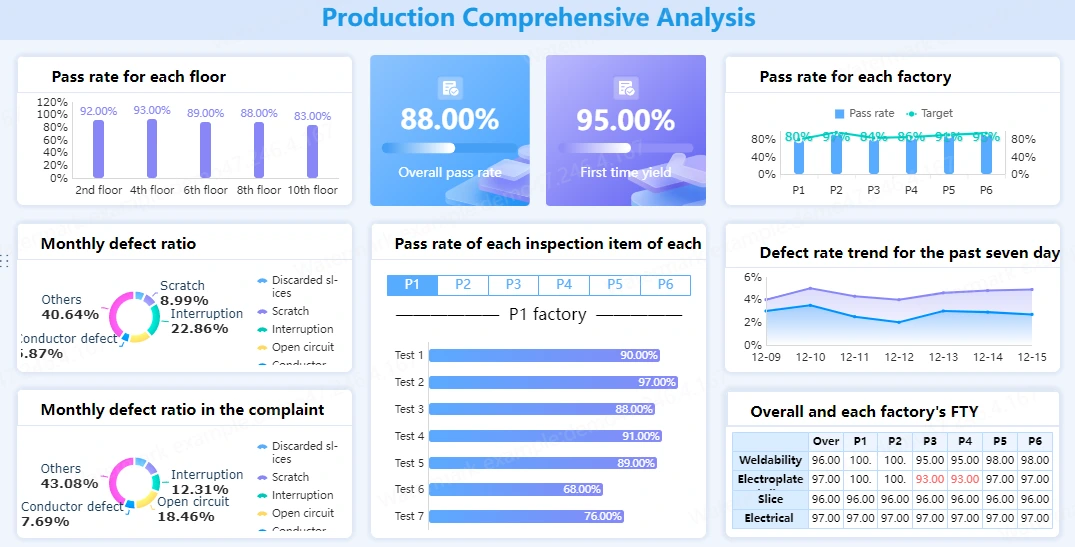
System Layers That Make Internal Ops Predictable
Not every layer is required on day one. We blueprint the full system during the Pilot, then implement only what your team can sustain.
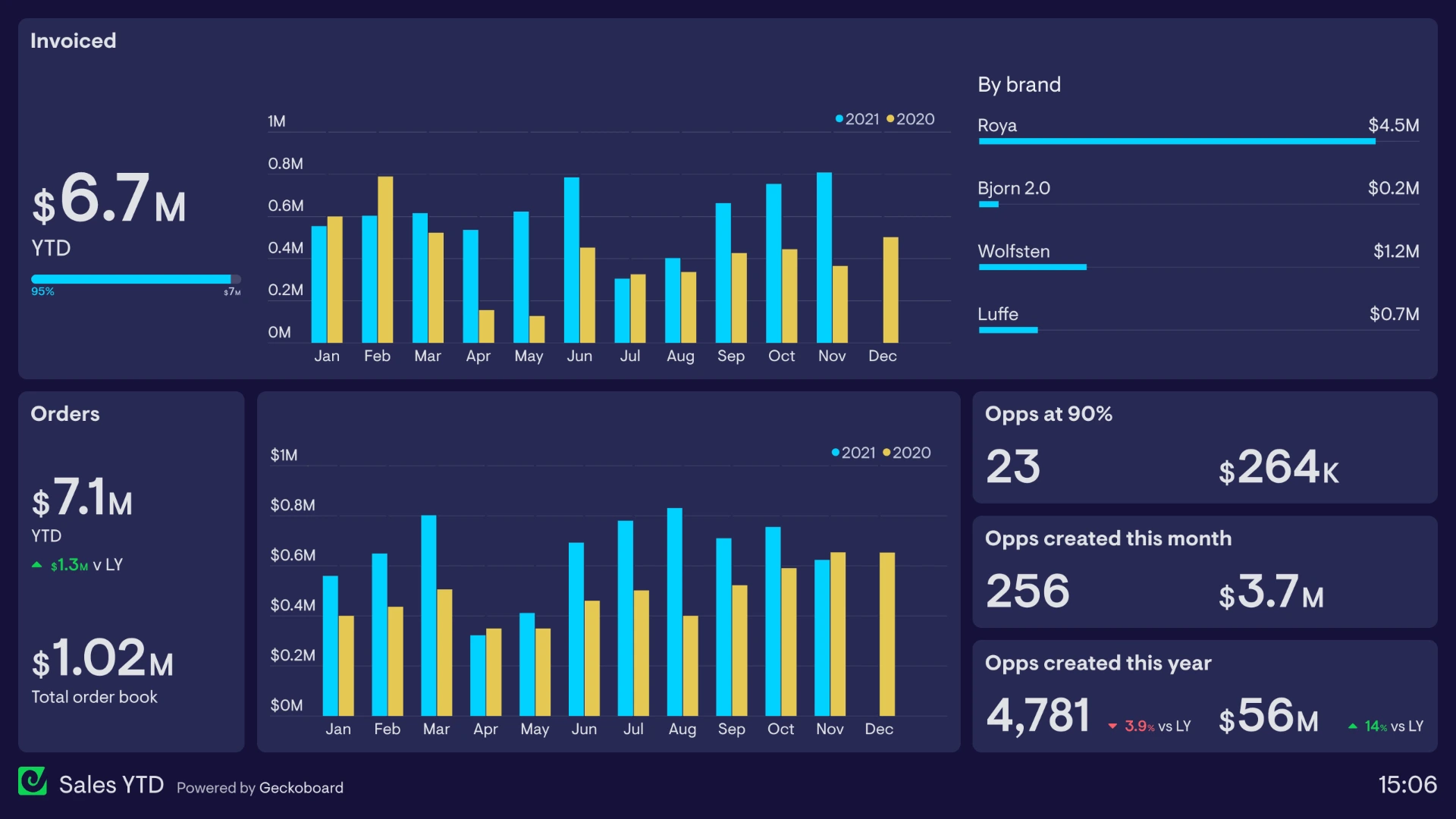
Signals We Typically Deliver
These are directional outcomes observed across internal operations contexts. Real measurement is defined during the Pilot.
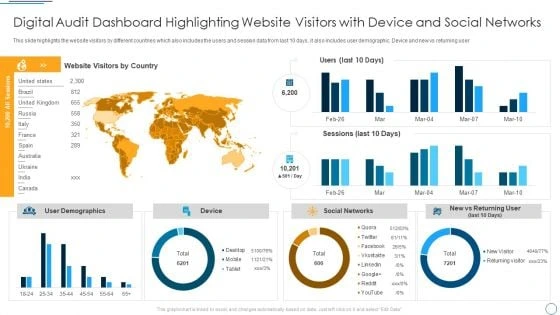
We stabilize internal operations so execution depends less on follow-ups and more on a system your teams can run. The Pilot validates where breakdowns happen, which rules matter, and what reporting leadership can trust.
Daily/weekly reporting becomes consistent without manual compilation.
Fewer follow-ups and fewer status meetings to “find reality.”
Exceptions surface early with clear escalation and accountability.
Where This Works Best
This is not “ops tooling.” It’s an operating model for teams that need predictable execution, governance, and reporting.
Works best for
- Multi-team or multi-location operations with fragmented updates.
- Workflows with approvals, evidence, SLAs, or compliance requirements.
- Leaders who need reliable rollups without micromanagement.
Not ideal if
- There’s no agreement on owners, stages, and escalation rules.
- The goal is “install a dashboard” without changing how work is captured and updated.
- Operations are too small/simple to justify standardization.
If This Matches Your Operating Reality
The next step is a Pilot — to map your internal workflows, define ownership and escalation rules, and validate reporting packs before scaling.
Start with a Pilot
We map intake, ownership, approvals, SLAs, and reporting rhythms. You get a blueprint and a validated operating model — before any system expansion.



